

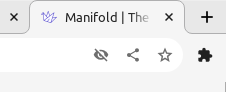
Here's a tab title in a typical crowded browser session. The title is clearly prefixed by the text "Manifold | The", but when I took a screenshot of the entire window and asked chatgpt4 what tabs I had open, it labelled it as:
Manifold Markets | x
Notice how it misread the x-shaped button as the letter x. It also knows that Manifold is a prediction market website with the domain manifold.markets, leading it to hallucinate "Markets" in the title.
Resolution criteria:
This market resolves YES if before 2025, any AI is able to reliably read the visible text of my browser tabs.
I'll sample my browsing history to randomly create 30 simulated browsing sessions, each with 12 tabs open. If the AI under test makes more than 1 mistake per 100 tabs (i.e. more than 3 mistakes), it fails.
The browsing window's y-position will be randomized and one other window will be open as a distraction (though not obscuring the browser tabs). The browsing window will always have the maximum screen width of 1920 pixels.
I will use the following prompt (h/t @Bayesian):
read precisely and accurately all the characters visible in my tabs' names.
 1,000
1,000 3.00
3.00@traders For practicality, I will just test with the most promising AIs. This will certainly include 4o and Claude 3.5 Sonnet, and whatever the equivalent is currently for Gemini (I'm not very familiar with it). If you want me to do others please mention them here.
@singer are you sure only 1 mistake per 100 tabs is human level? but anyway I tried it a few times with 4o and it was correct. It'll probably be more robust with common tabs than with rare / arbitrarily complex tab strings.
Prompt was:
read precisely and accurately all the characters visible in my tabs' names.
are you sure only 1 mistake per 100 tabs is human level?
I'm not. I dislike how I previously had invoked that concept.
I've removed the vague language that wasn't doing any work in the criteria, so now it's just the procedure itself. From my perspective the interpretation is unchanged but anyone can ask for a refund if they want via DM @traders
It'll probably be more robust with common tabs than with rare / arbitrarily complex tab strings.
Yes, and I have strong doubts that it will make less than 10 mistakes total, but haven't tested it myself yet.
@Bayesian just tried with my current tabs now, and claude 3.5 sonnet fails (using the same prompt as you). The culprit was non-English text.
Roughly human level. I'd only permit 1 mistake per 100 tabs. I'm giving it the chance to do multiple chain-of-thought steps (internally it can; I'm not giving it multiple attempts per trial), so it has all the "time" that a human would have to double check their answer. This is in contrast to running something like llava-v1.6-34b directly on a screenshot which has to output an answer immediately without reflecting on it.
edit: see the updated criteria