

Open source models are measured against ARC, HellaSwag, MMLU, and TruthfulQA on https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard . I've added the following plot to this huggingface space so we can see the progress of open source models over time:
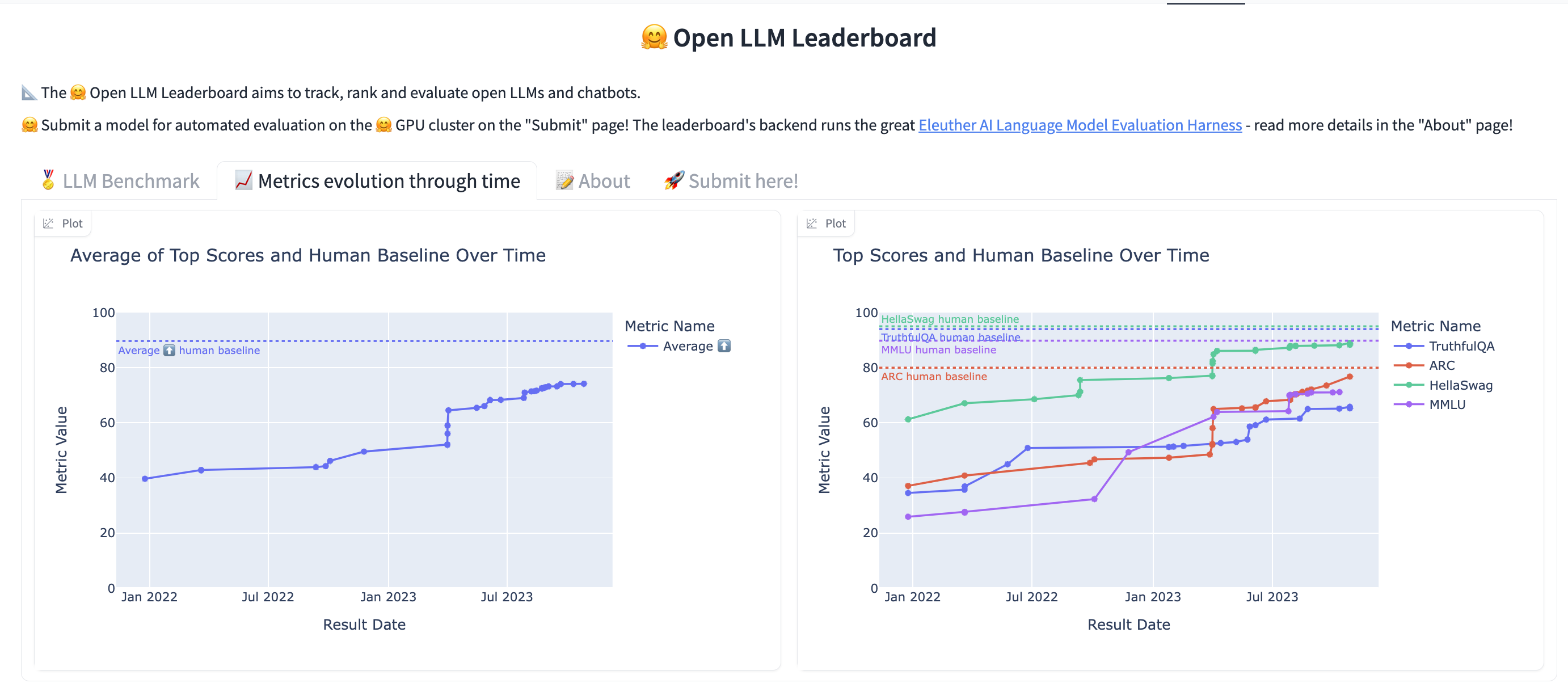
I'm wondering when the average human baseline will be passed. A linear trend indicates July 2024 with a 0.89 pearson coef:
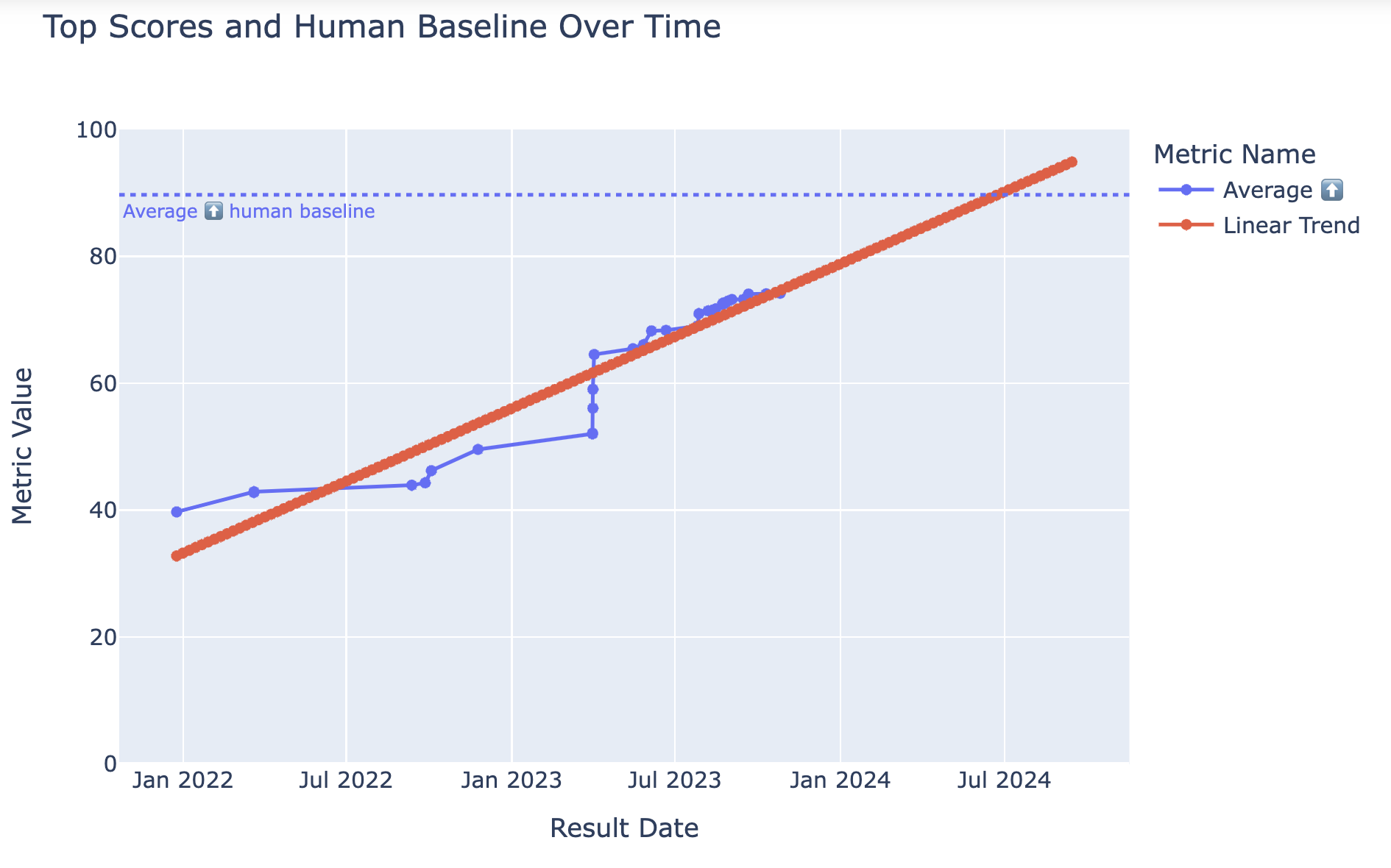
But this trend might not be linear. This questions will resolve Yes if the average human baseline on Open LLM Leaderboard on huggingface is surpassed before July 1, 2024.

 1,000
1,000 3.00
3.00"an average human" in the title is misleading given that "average human baseline" consists of MMLU human baseline at ~90% which is expert performance instead of average human performance.
from: D. Hendrycks, C. Burns, S. Basart, A. Zou, M. Mazeika, D. Song, and J. Steinhardt. Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300, 2020
https://arxiv.org/pdf/2009.03300.pdf

@Metastable yeah it's so hard to measure these things. Don't worry I have an idea to fix this.