In Feb 2022, Paul Christiano wrote: Eliezer and I publicly stated some predictions about AI performance on the IMO by 2025.... My final prediction (after significantly revising my guesses after looking up IMO questions and medal thresholds) was:
I'd put 4% on "For the 2022, 2023, 2024, or 2025 IMO an AI built before the IMO is able to solve the single hardest problem" where "hardest problem" = "usually problem #6, but use problem #3 instead if either: (i) problem 6 is geo or (ii) problem 3 is combinatorics and problem 6 is algebra." (Would prefer just pick the hardest problem after seeing the test but seems better to commit to a procedure.)
Maybe I'll go 8% on "gets gold" instead of "solves hardest problem."
Eliezer spent less time revising his prediction, but said (earlier in the discussion):
My probability is at least 16% [on the IMO grand challenge falling], though I'd have to think more and Look into Things, and maybe ask for such sad little metrics as are available before I was confident saying how much more. Paul?
EDIT: I see they want to demand that the AI be open-sourced publicly before the first day of the IMO, which unfortunately sounds like the sort of foolish little real-world obstacle which can prevent a proposition like this from being judged true even where the technical capability exists. I'll stand by a >16% probability of the technical capability existing by end of 2025
So I think we have Paul at <8%, Eliezer at >16% for AI made before the IMO is able to get a gold (under time controls etc. of grand challenge) in one of 2022-2025.
Resolves to YES if either Eliezer or Paul acknowledge that an AI has succeeded at this task.
Related market: https://manifold.markets/MatthewBarnett/will-a-machine-learning-model-score-f0d93ee0119b
Update: As noted by Paul, the qualifying years for IMO completion are 2023, 2024, and 2025.
Update 2024-06-21: Description formatting
Update 2024-07-25: Changed title from "by 2025" to "by the end of 2025" for clarity
 1,000
1,000People are also trading
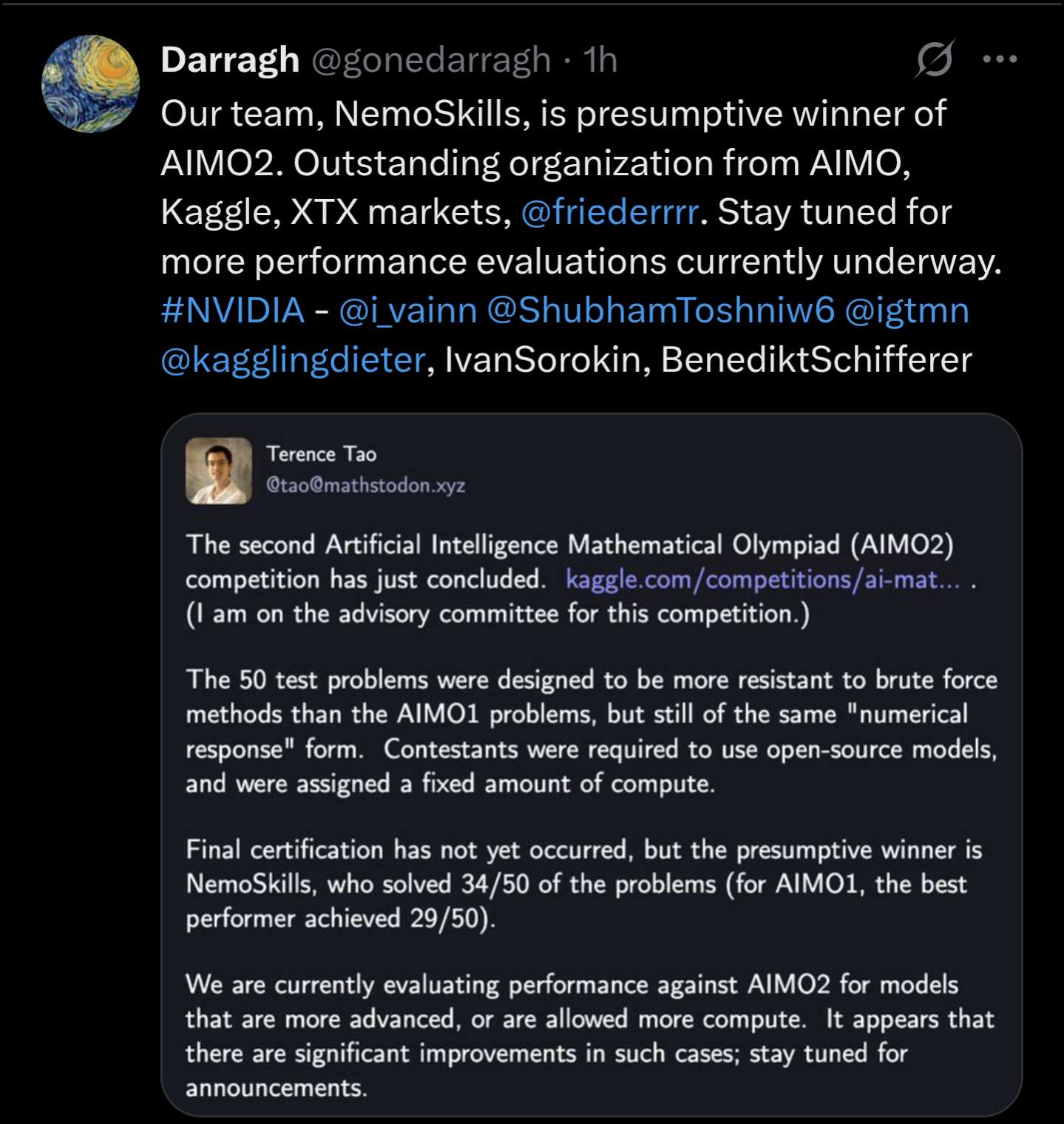
@MalachiteEagle these are open source efforts. They have great progress for math-oriented LLMs but still fall short of state of the art proprietary solutions. AIMO2 problem difficulty is a level below IMO
@MalachiteEagle It cannot do combinatorics, and last year it arguably got lucky with the functional equation at #6. Can it do all kinds of algebra problems? Also 4.5 hours, last time it took days.
@nathanwei you don't think o4 is going to be good at combinatorics? I haven't seen much info on o3's capabilities in this domain
@MalachiteEagle I mean o3 completely sucks at olympiads - see https://manifold.markets/Austin/will-an-ai-get-gold-on-any-internat#e41lre4y806 - so I was thinking more AlphaProof than o4.

@nathanwei that's o3-mini though right? If OpenAI does an attempt they're not likely to use such restricted inference compute
@MalachiteEagle even with a lot of inference compute o4 would probably still suck at a bunch of types of problems.
@Bayesian I'm willing to believe that's true, but I think it's plausible that o4 is going to be good enough to get gold on many olympiad problems
@MalachiteEagle "get gold on many olympiad problems" do you just mean it'll be good enough to solve some problems? if so I agree
@Bayesian yeah I meant accurately solving problems in a way that doesn't look too weird, like not 500 pages of equations or something
Leading LLMs get <5% scores on USAMO (which selects participants for the IMO): https://arxiv.org/abs/2503.21934
@JimHays Oh, for sure; and LLMs were never the most likely avenue for this to be achieved.
I just think there is a certain current of thought in the AI hypersphere (which includes a lot of Manifold) for which this result should be a big update.
@mathvc No, leading AI systems did, but not LLMs.
AlphaGeometry is a neuro-symbolic system made up of a neural language model and a symbolic deduction engine, which work together to find proofs for complex geometry theorems. Akin to the idea of “thinking, fast and slow”, one system provides fast, “intuitive” ideas, and the other, more deliberate, rational decision-making.
AlphaProof is a system that trains itself to prove mathematical statements in the formal language Lean. It couples a pre-trained language model with the AlphaZero reinforcement learning algorithm, which previously taught itself how to master the games of chess, shogi and Go.
So while these systems include language models, they are not themselves LLMs, it’s not the language models that are doing the heavy mathematical lifting.
@JimHays I don’t know who taught you all these words but AlphaProof is LLM with tree search on top. Tree search is literally sampling (i.e. one of many ways to use LLM)
There is nothing neurosymbolic in it. It’s just a fancy words used by people who don’t know Lean.
@mathvc Take it up with the creators of the models then. I’m quoting from their blog posts announcing the results. They say that their systems include, but are not limited to, language models.
https://deepmind.google/discover/blog/ai-solves-imo-problems-at-silver-medal-level/
https://deepmind.google/discover/blog/alphageometry-an-olympiad-level-ai-system-for-geometry/
@JimHays you confused AlphaProof with AlphaGeometry then. The quotes are about AlphaGeometry, it isn’t LLM. AlphaProof is nothing more than LLM
Wikipedia says:
AlphaProof is an AI model, which couples a pre-trained language model with the AlphaZero reinforcement learning algorithm.
AlphaZero (AZ) is a more generalized variant of the AlphaGo Zero (AGZ) algorithm, and is able to play shogi and chess as well as Go.
I’m not sure why you consider that to be nothing more than an LLM?
@JimHays yes i do because i understand what is “AlphaZero” and implemented it many times myself for combinatorial search.
It’s a sampling technique on top of LLM (or on top of any policy network in RL environment).
There are tons of ways to change sampling from LLM (eg change temperature, best of k, maximum likelihood, etc), it doesn’t turn it into non-LLM
You can bet more on NO instead of arguments
@JimHays DeepSeek has paper that gives much more details on LLMs+TreeSearch https://arxiv.org/pdf/2408.08152