(Mostly self-explanatory. To clarify, GPT 4.5 or GPT-5 would count. A new version of GPT-4 with a larger context window won’t)
To clarify further: to count as more capable, the LLM should be able to be better across benchmarks relevant to capabilities while not performing worse on some benchmarks relevant to capabilities.
Related questions
@Joshua GPT-4o seems worse than GPT-4 in my personal experience and it’s worse on some benchmarks, so I’m probably not going to count it. But maybe I’m wrong/can’t prompt/etc., and maybe some independent benchmarking showed something different? Feel free to share links if so. By default, I’m waiting for GPT4.5 (or GPT-5). I’d be somewhat surprised if it doesn’t come out until the end of summer.
@ms Sold my shares, but I think there is a strong case to make for it counting. I don't think there will be GPT-4.5, nor will GPT-5 come out this summer. This is what migth have been named GPT-4.5, and it's not as exciting as many people had hoped but part of that is that the most exciting part is that it's free and natively multimodal, not that it's massively smarter.
It is, however, smarter. Not massively smarter, but definitely still more capable! You asked for independent benchmarking, and I'm not sure why we would have reason to doubt OpenAI's own benchmarks showing that it's better than 4T and all other models at the vast majority of tasks but here's an independent comparison:
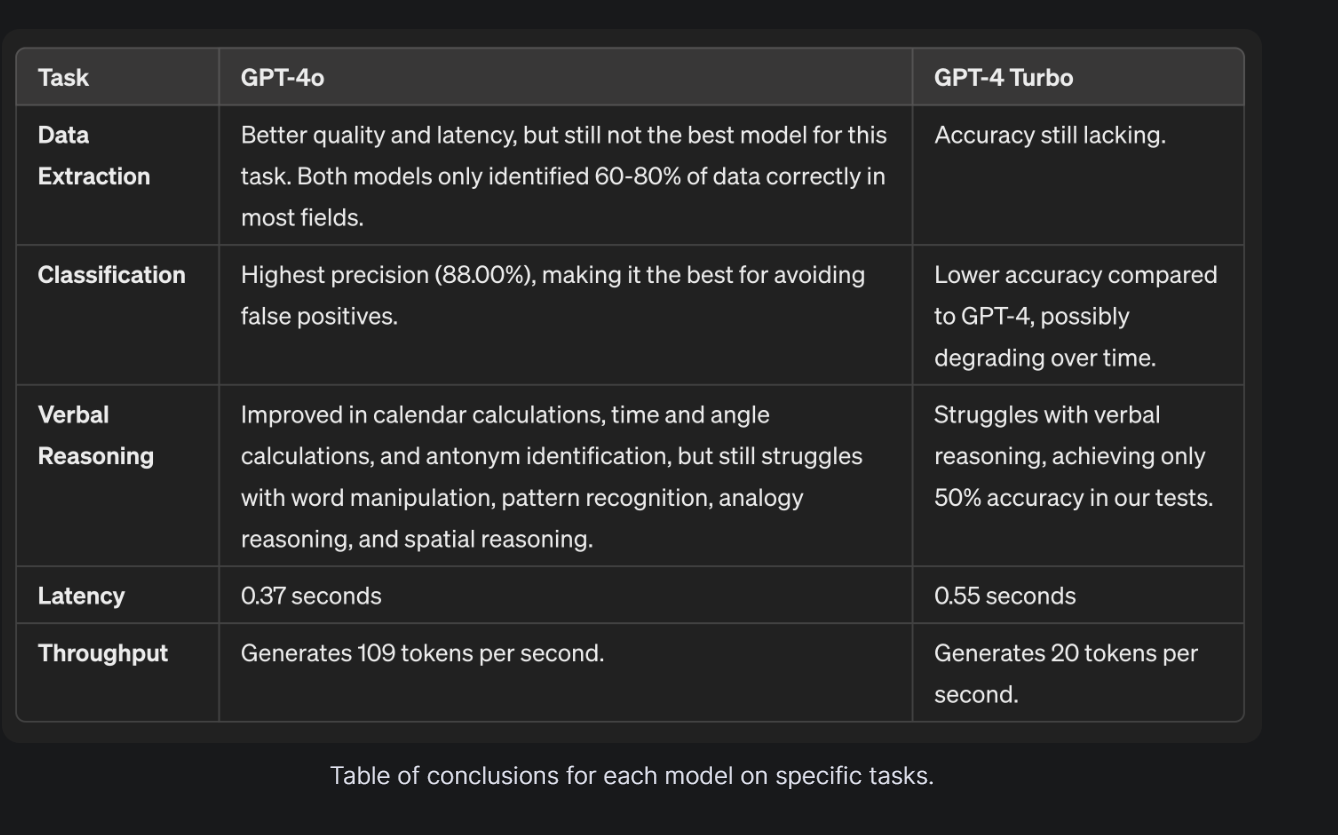

Here's another independent comparison:
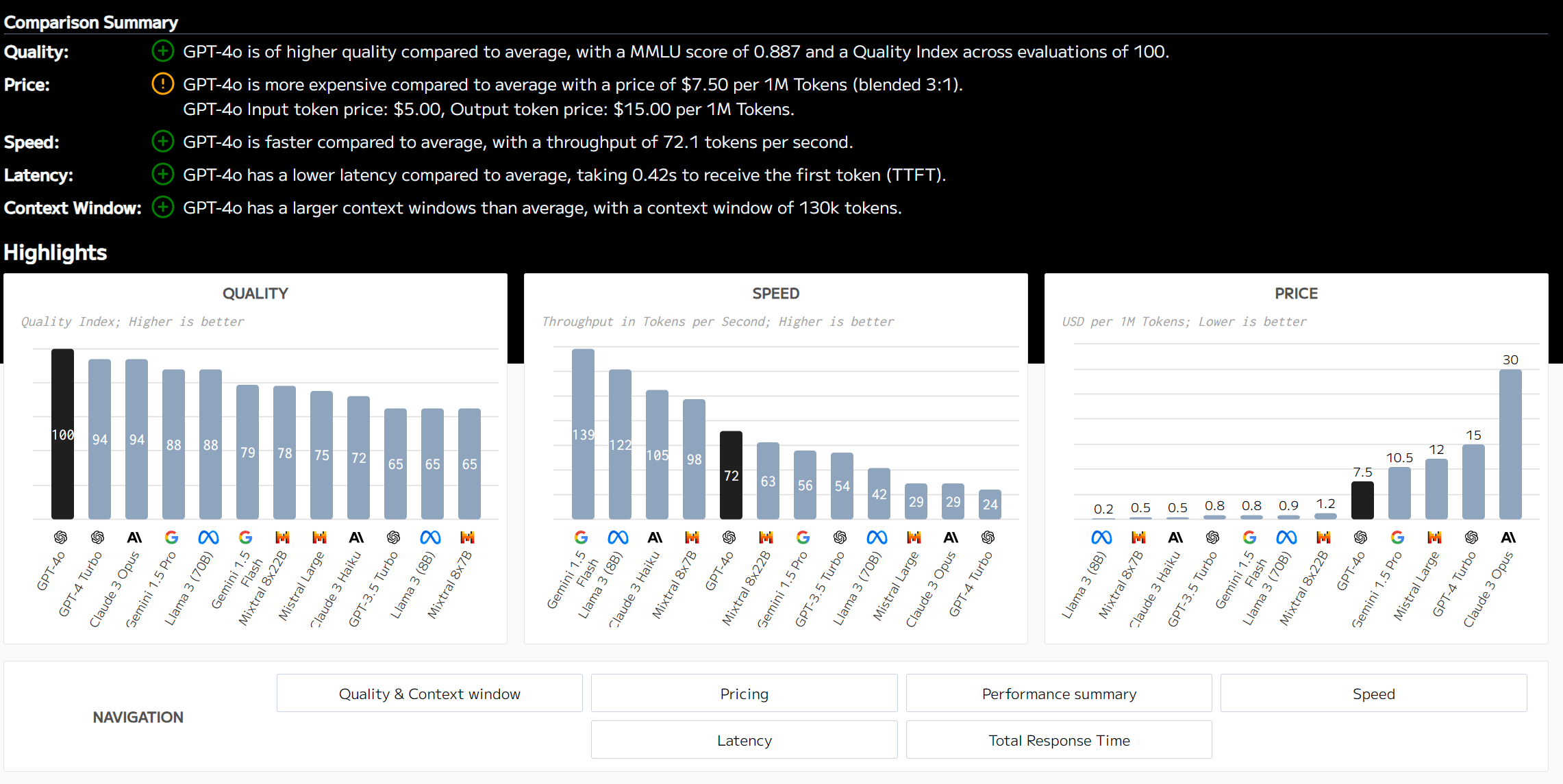
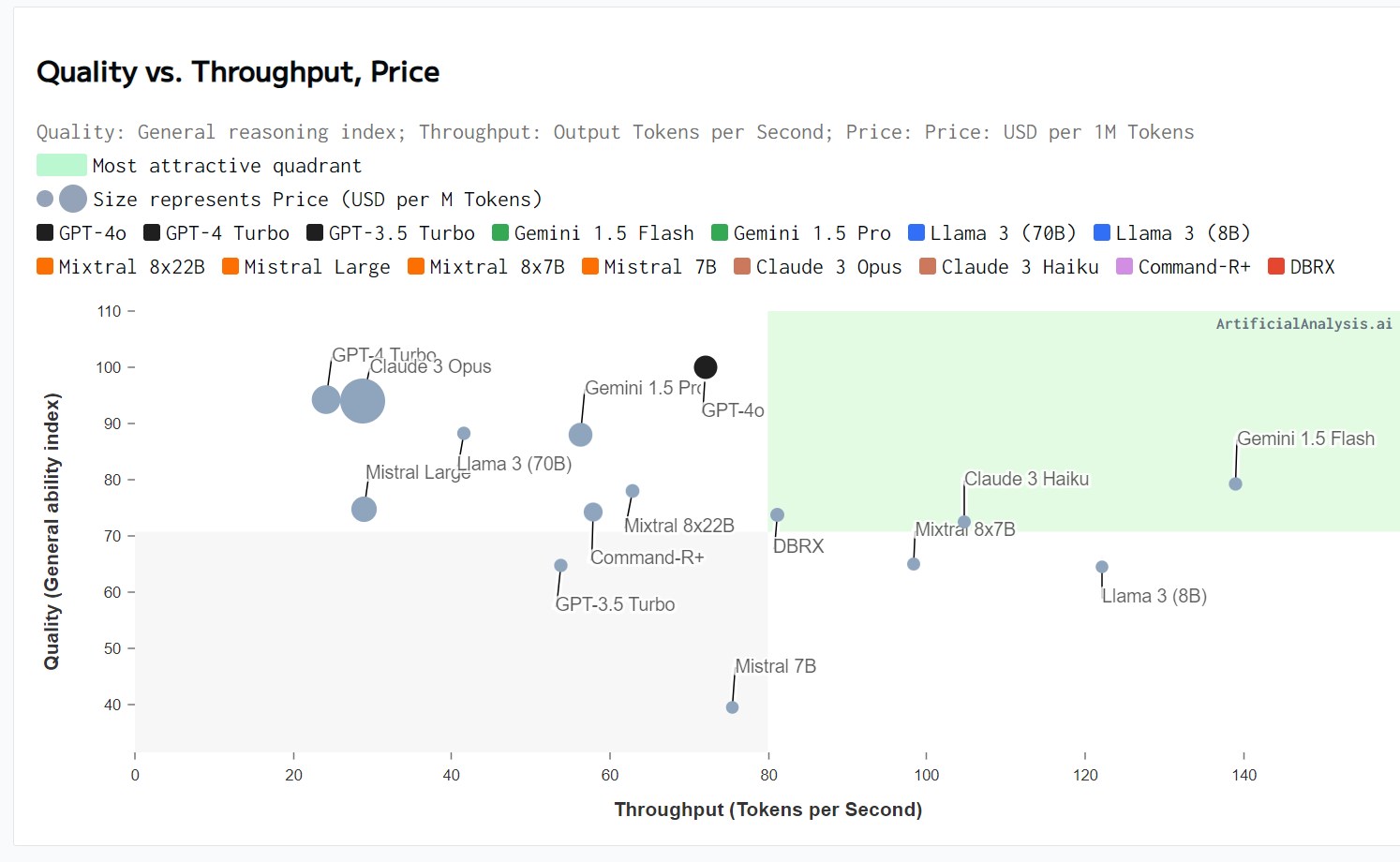
I don't think OpenAI is wrong to say it's the best model in the world. It's only the best by a small amount, but the fact that it's the best while also being massively faster, cheaper, and multimodal is genuinely very impressive.
All that said, it's not better than every model at everything, including GPT-4 Turbo. Turbo is sometimes better than it at some things, though very rarely and always more slowly and more expensively. 4o is most impressive when you're talking to it in real time, which isn't captured by any of these numbers.
So I think it's a yes, but I see why you wouldn't count it. Especially since the audio features aren't even rolled out yet. Up to you, of course.
Does any of this change your mind?
(disclaimer: I have a position on this market, and I know less about this than joshua does, and I am not speaking in my capacity as a moderator, just stating what I think are my honest opinions / beliefs)
I think the benchmarks seem consistent with GPT-4o being a faster, cheaper, and maybe or maybe not smaller model, that still reaches a similar raw INT score to GPT-4 turbo (not clear if slightly better or slightly worse; my guess is slightly worse), but whose RLHF and finetuning is weaker and more focused on giving answers that are pleasing to the user.
Essentially, a more "capable model" should be more able to answer difficult questions about a wide range of topics, imo. It should do better on things like the bar exam, math olympiad questions, be more persuasive, etc. A model that is faster, cheaper, and accepts to answer more questions, and has been optimized to format answers in a more pleasing way (to the user), is not imo more capable. Impressive, yes; a good financial move, definitely. When GPT-4 was released (https://openai.com/index/gpt-4-research/), there were a set of benchmarks with their scores, shown as proof that it is capable. I haven't seen people use those benchmarks to show GPT-4o is more capable than GPT-4, which I have seen for GPT-4 turbo, and which I would have expected to be thrown around a lot more (as proof that gpt-4o is most capable) in worlds where gpt-4o was actually smarter than gpt-4 turbo.
Moreover, my limited look at the benchmarks that are actually shown, is that they're either pretty vague in a way where speed and better rlhf could be affecting the result, or they're about writing / creativity / in context learning, which would be expected to be slightly better, from a slightly worse model with laxer rlhf.
I welcome others to show me why this view is inconsistent or improbable.
@Bayesian I posted this before, but the model announcement page does have benchmarks: https://openai.com/index/hello-gpt-4o/
GPT-4o scores higher than GPT-4 Turbo on MMLU, MATH, etc. These are not subjective measures.
@Bayesian they're not subjective, but there is, as I understand it, an eval treadmill always turning where models are more or less trained to do well on evals such that, over time, existing evals become worse proxies for capabilities and fresh ones are needed. This is true even if models aren't literally training on the eval data.
This is one reason people started relying on chatbot arena so much, it seemed harder to game. But not impossible, and there's some skepticism of chatbot arena results as well. People prefer the model, but for what reason? Do they just like its tone more, or that it responded faster? Did it compliment their dashing haircut? Reasons for doing well in chatbot arena might not always be what we think of as "capabilities". And they literally put three model variants up and picked the highest-scoring one to release.
I forget where I read it but there was a claim that GPT-4o's better performance in various evals, chatbot arena included, is in large part due to a lower rate of refusal - i.e. the model less often says "I'm just an AI model, I can't do that" or it would be unethical for me to do that" or whatever, for a task that it is very much capable of (and is not particularly unethical). Is "fewer false positives in RLHF-induced guardrails" synonymous with "more capable"? I think you could argue that either way.
This leaderboard has been doing the rounds in recent days, showing (large error bars notwithstanding) GPT-4 turbo outperforming GPT-4o in some categories, and not in others. These are evals with private data that the company claims are hard to game, but skepticism is warranted:
The improvements to multimodal input and output are definitely improvements though, and if the creator wants to count that as "more capable" then I won't complain too much. And if my arguments about gameability of evals seems like special pleading, that's a fair enough complaint - I don't know how seriously to take such things. If the improvement in capabilities as per evals were less marginal though, it wouldn't matter since it would be obvious.
And on openAI's benchmarks page there, GPT-4o doesn't outperform Turbo on all evals. It's worse at DROP, whatever that is.
that's interesting and makes a lot of sense so ty for the reply :p leaderboards like scale.com's seem pretty valuable considering the progressive worsening of imperfect and gameable public evals! as long as they keep their integrity and you can't test 10 different models on it and pick the best one, ofc
@ms Looks like a strong case for the second half of the year: https://www.axios.com/2024/05/13/openai-google-chatgpt-ai
4.5 or 5.0 are forthcoming, and OpenAI does not consider this to be the next level yet.
@jacksonpolack Yeah the dropdown wasn't including him on mobile. Happens often with very short @ names.
If GPT-4o doesn't cut it, then 2025+ is massively underpriced imo.
@Sss19971997 Unfortunately it appears to be doing worse on one and therefor the market maker will likely say it doesn’t count
@Panfilo That seems like a weird interpretation to me. Just because it performs slightly worse (could be a insignificant difference) on a single benchmark that shouldn't make this resolve NO, imo.
@ErikBjareholt The negative condition at the end of the description would indicate it’s a No, and similar markets have started resolving (though of course phrasing matters).
@Panfilo I'm not super sure how these markets should resolve but oh God let's please not cite Jim's decisions as if they should be precedent
@Joshua I probably want to wait to see the capabilities improvement (via benchmarks). Human preference alone and anecdotal evidence from people who’ve interacted with it via the arena isn’t sufficient, have to wait for a confirmation it can solve more tasks, will resolve once we see that. If resolves, this probably shouldn’t take long?
@Joshua If it's more than just a larger context window, it should count based on the description.
@Panfilo if there are things that work together with the LLM (such as voice), it doesn’t count. The LLM has to perform better across benchmarks relevant to capabilities and not perform worse on some benchmarks. I previously clarified this in the comments but didn’t put it in the description, sorry.
@ms Are you saying 4o has to outperform 4T on every single benchmark? Or would doing so on a large majority be enough to count as more capable? The fact that it's half the cost and twice as fast must come with some drawbacks.
@ms Benchmarks can be found here: https://openai.com/index/hello-gpt-4o/
It does better than GPT-4Turbo on every benchmark shown except DROP. How does that resolve?