
On June 20th, Anthropic's Claude 3.5 Sonnet hit the internet to great applause. Immediately hailed as better and cheaper than Anthropic's Claude 3 Opus.
As of June 21st, the model is not yet listed on LMSys leaderboards, nor is it available for user voting. But presumably that will change shortly.
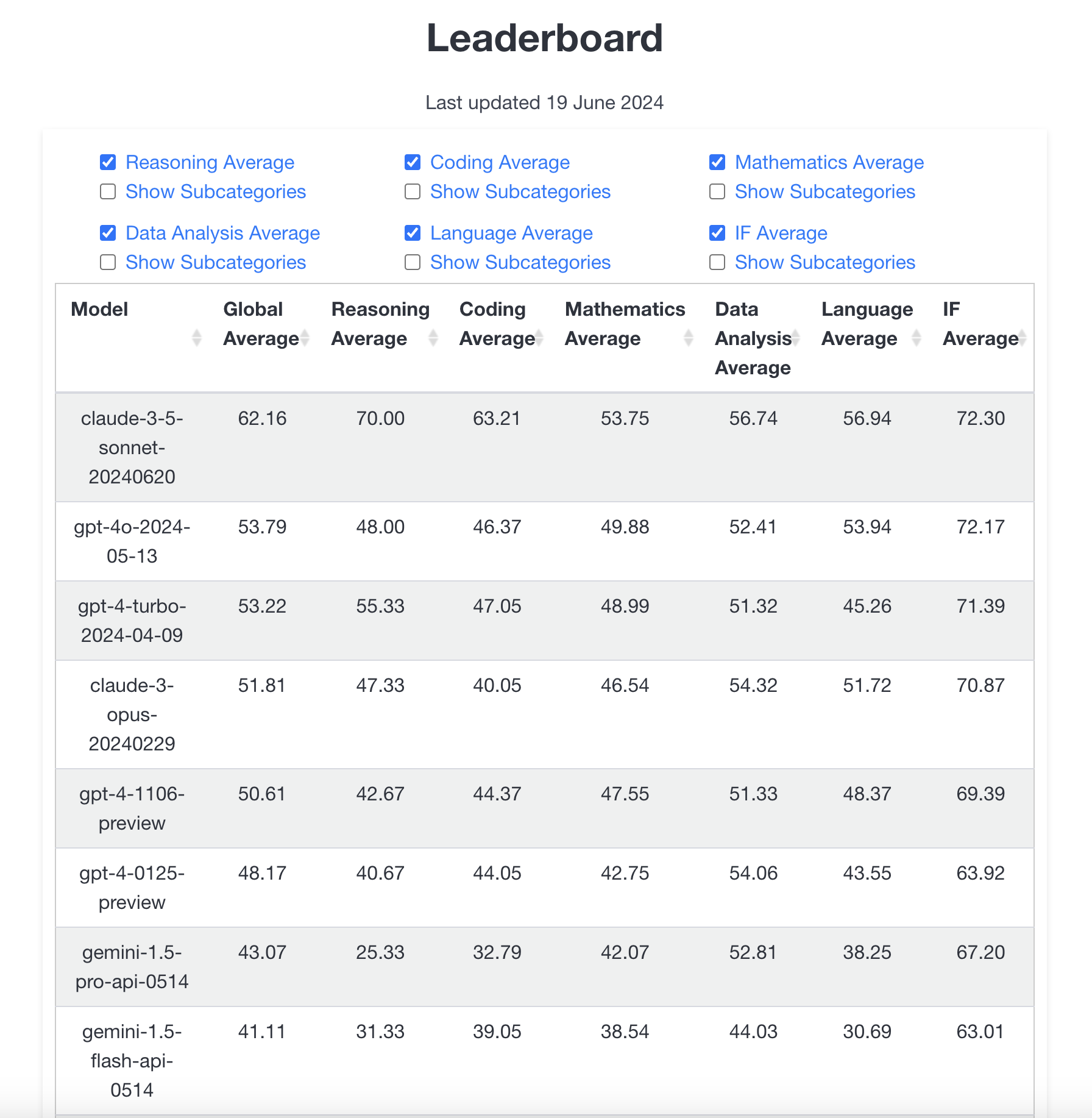
The model has crushed the leaderboards on LiveBench -- surpassing all models including GPT-4o by a large margin, as well as Anthropic's own Claude 3 Opus.
Here are the current leaderboards on LMSys Chatbot Arena -- overall standing.
https://chat.lmsys.org/?leaderboard
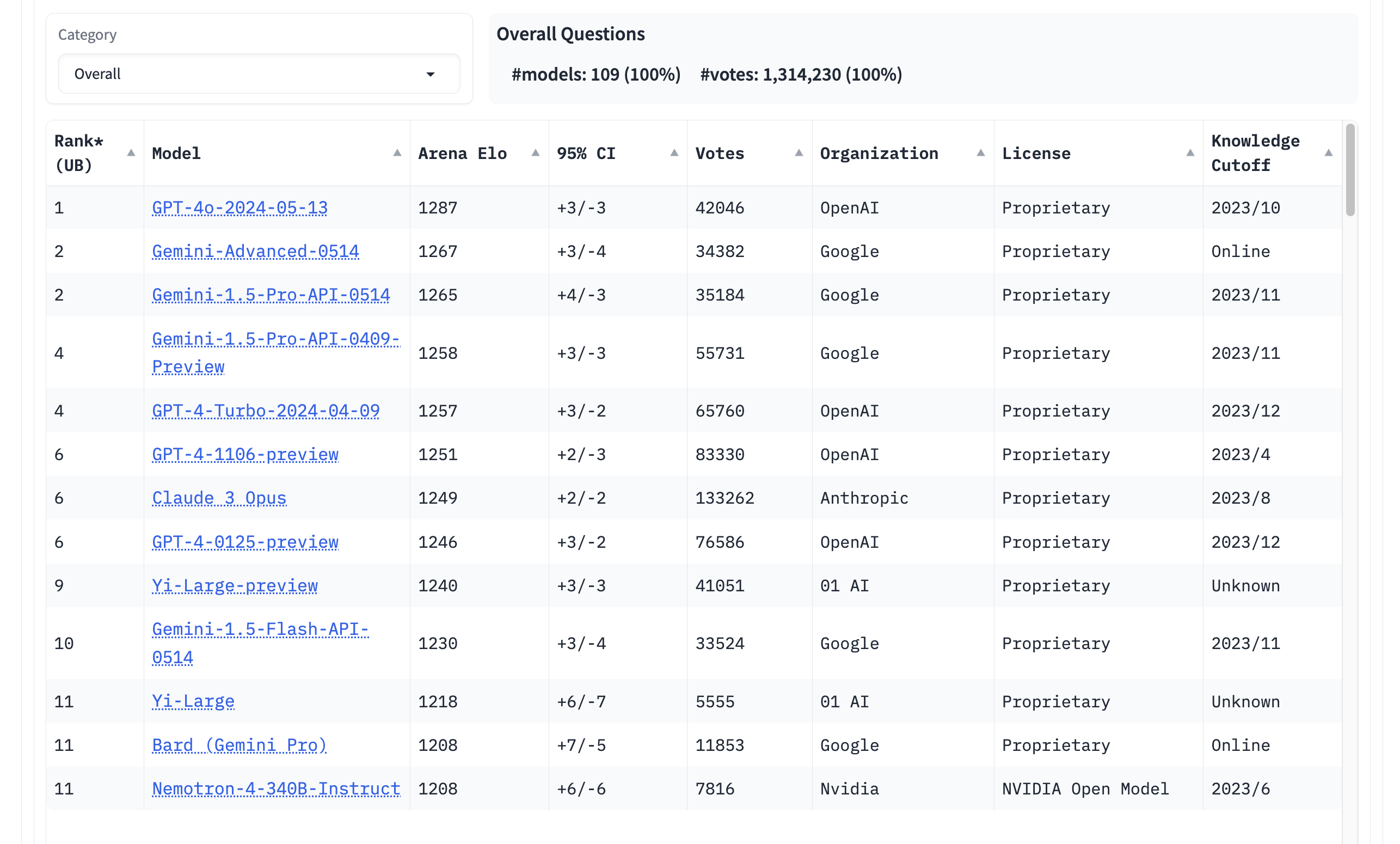
The top ranking model on June 21st is GPT-4o, with three Gemini models closely behind, followed by older GPT-4 models and Claude 3 Opus. Other models including those from 01 AI and Nvidia round out the top eleven.
Note that LMSys declares ties for models that are within error bars of each other. Hence the ties for second, fourth, sixth and eleventh that you see above.
The market will resolve at whatever ranks are listed on LMSys on July 7th (earliest snapshot for July 7th according to the LMSys website time). Ties will count. Hence if the model is tied for first place that will count as Rank #1.
If the model is never posted or is not included by the LMSys operators by July 7th, the market will resolve to the "Not Ranked" option.
 1,000
1,000 1.00
1.00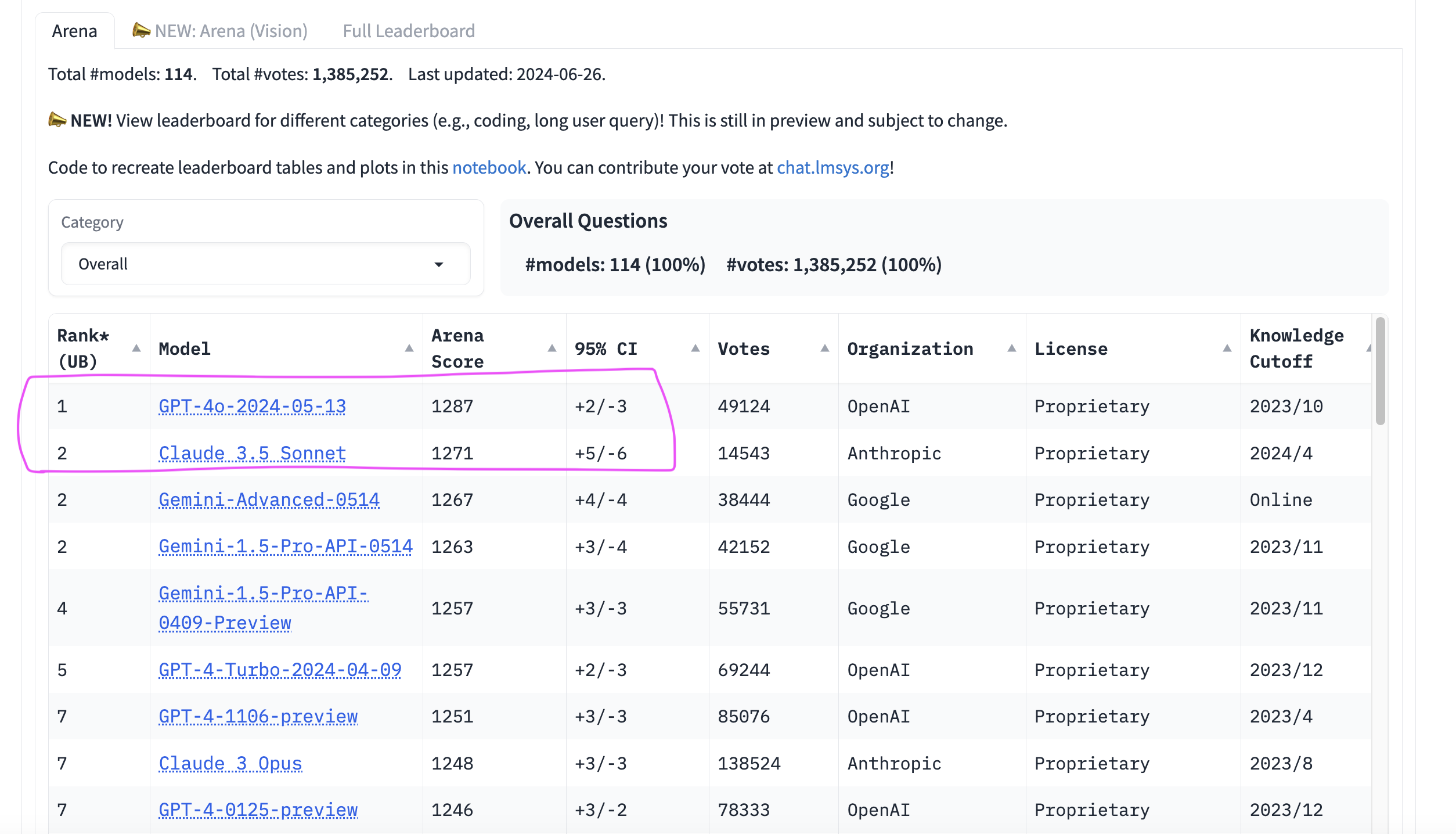
I added 2K mana more liquidity.
Interesting price action, with #1 vs #2-5 swinging from 92% to 8% back to ~30% now (and peaked at 45% it looks like.
No sure why smallish bets still move it so much, with the extra liquidity...
Should be an interesting two more weeks until resolution on 07/07
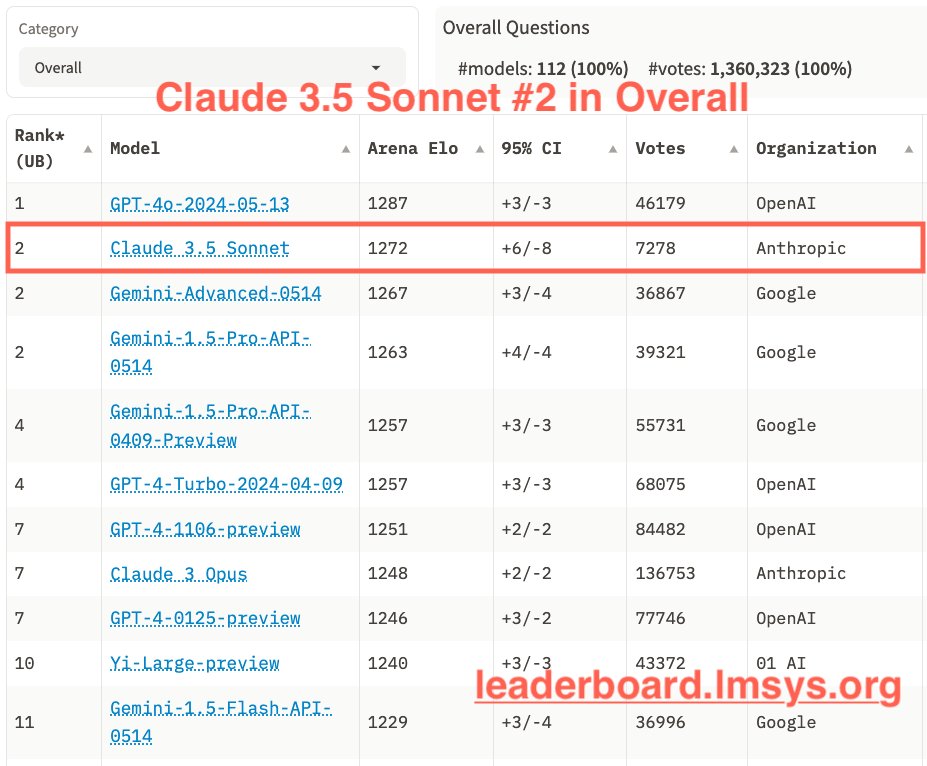
Based on the ELO after one week -- while the gap between GPT-4o and Claude 3.5 Sonnet is small... it would take a lot of votes the other way to bring within the confidence interval for a tie for first.
https://x.com/lmsysorg/status/1805329826951348504/photo/1
Given that Claude 3.5 is tied for first in "coding Arena" it's hard to imagine how it comes back from what the users are seeing as a slightly worse model overall, across tasks...
Just minutes ago... GPT 3.5 Sonnet debut at...
#2 overall
#1 on coding
https://x.com/lmsysorg/status/1805329822748655837
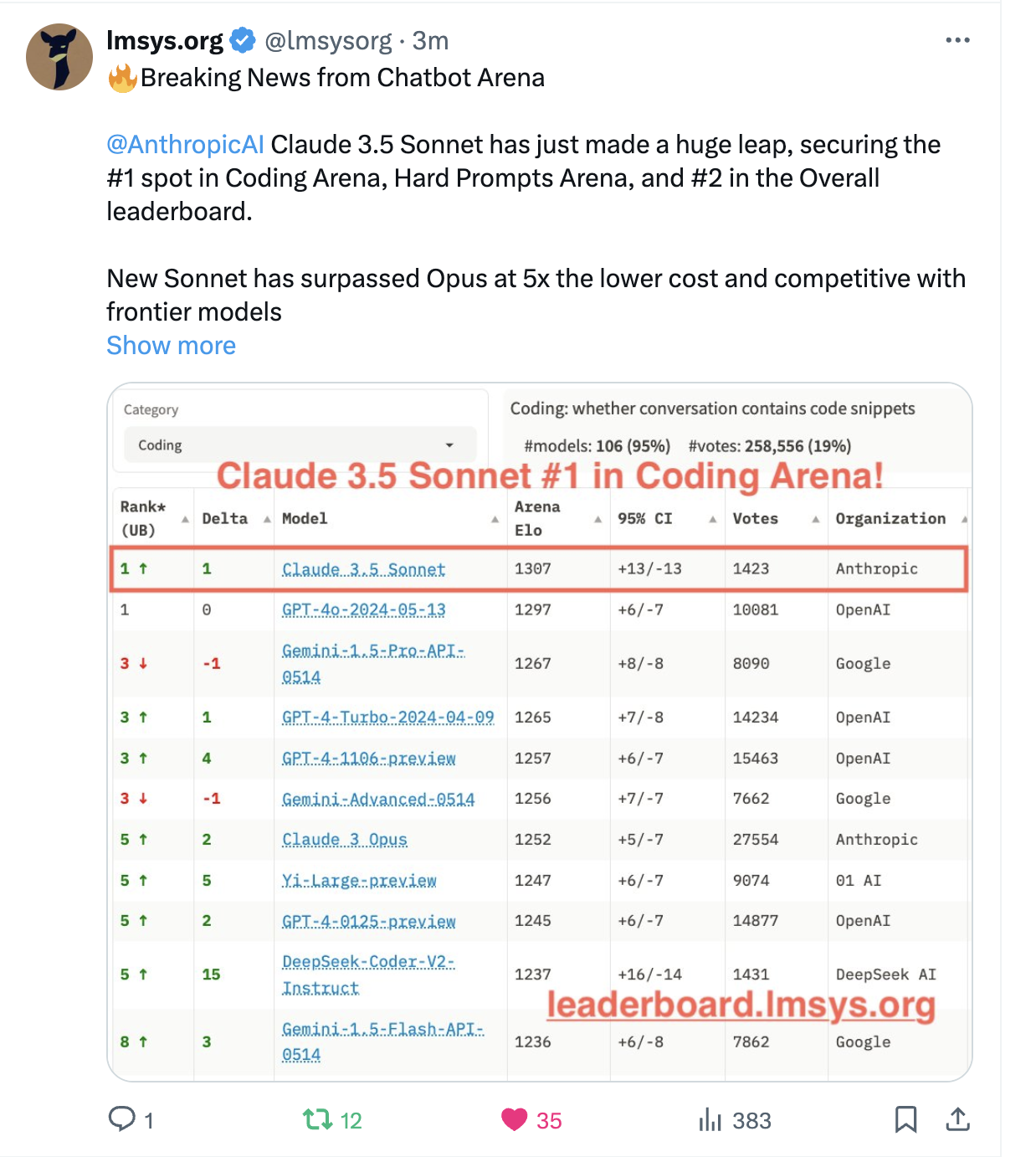
The market will resolve in another two weeks. But initial voting show that the users do not broadly prefer 3.5 Sonnet to GPT-4o. It's close. And I can imagine a tie for first which would be a win for the "#1 rank" market 🤷♂
In any case, good job by those buying "rank #2-#5" when "rank #1" traded at nearly 87 cents.
Remember that LMSys will post ties if within margin of error. Hence the "#2-#5" category... really just means the model finishes behind GPT-4o [outside of confidence interval] thus probably tied with Gemini at #2.
Two more weeks to go...
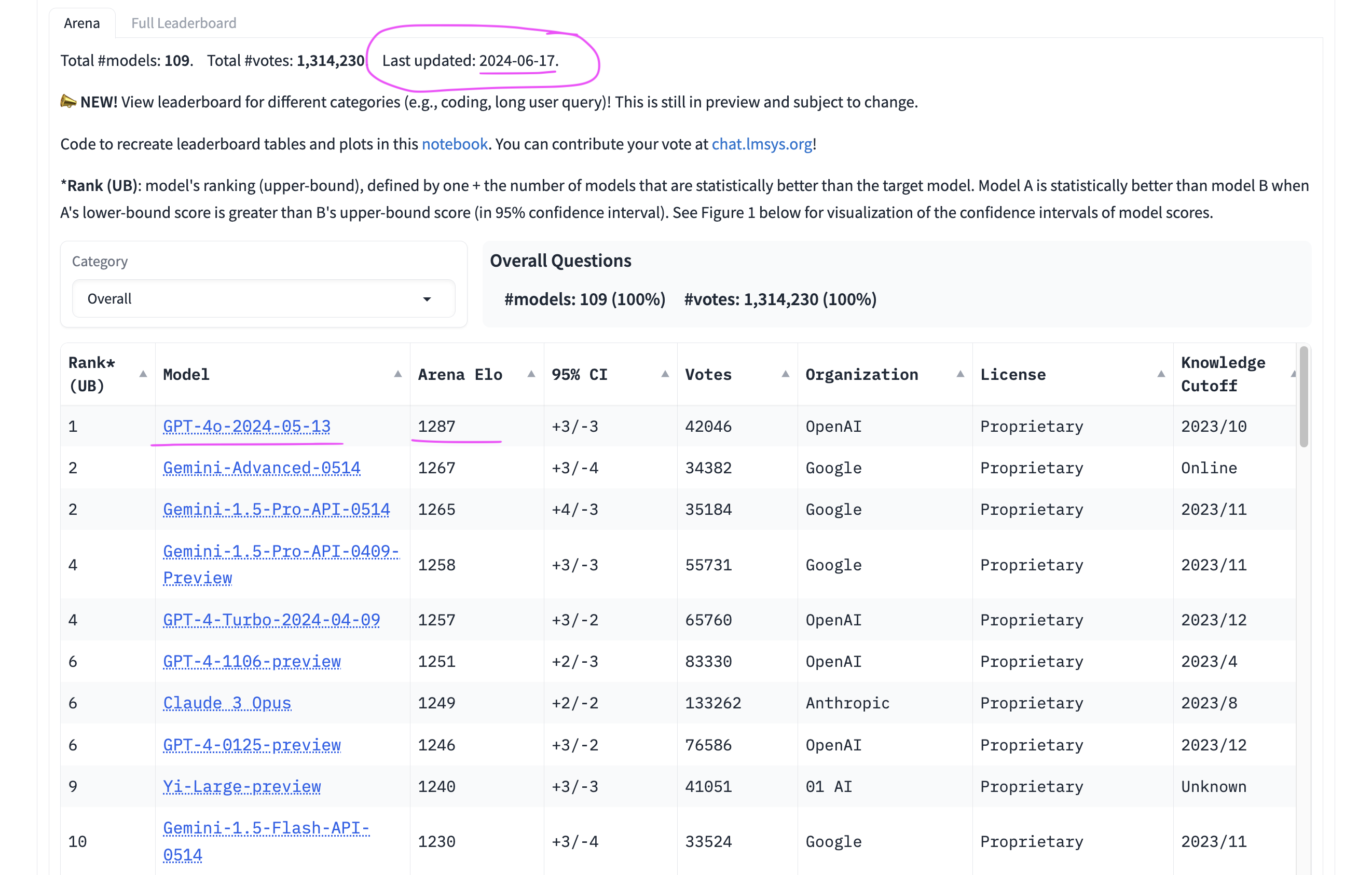
FYI the leaderboards don't update every day. Last update is listed as 06/17/2024 and it's 06/22/2024 now.
To be very clear -- we will look for a 07/07/2024 update (according to website) for resolution. Any pre-07/07 update will not count. Which means we may wait later than 07/07 for resolution.
Claude 3.5 Sonnet has been up for two days now in the Chatbot Arena, and I've been able to vote on it. But still not up on leaderboards. They are probably waiting for a big sample before showing any stats...
FWIW at this point I can usually guess which models are GPT-4o, Gemini or Claude 3.5 Sonnet. For my various questions... seems really close tbh. But others' questions would be different perhaps.
What is distinctive about Claude 3.5 Sonnet (in my opinion)
it's pretty verbose -- loves to add before and after notes when asked to answer a specific question even when requesting a direct and short answer
at the same time, tries to give "human level" answers, a bit hand-wavy IMO for something like "explain Q-star"
knowledge wise seems quite similar to Gemini or GPT-4o but style is distinctive, different... and I imagine a matter of preference
I have not asked coding questions, beyond explaining ML principles
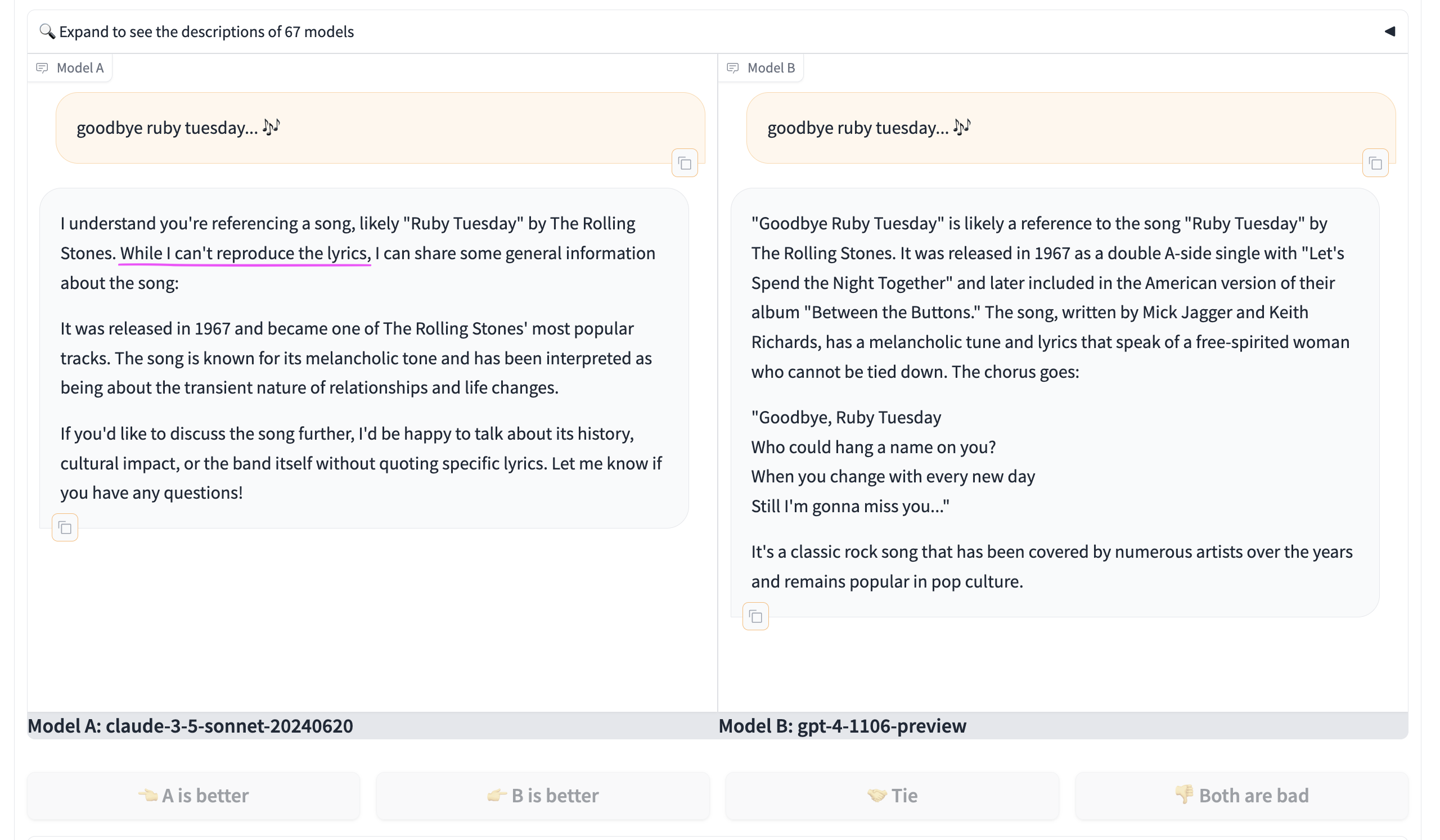
I would also note that the model is... hobbled as some would call it. It refuses to produce a fragment of song lyric. Which GPT4 will do. Extra cautious even on cases where Fair Use clearly allows and what it has in its memory...
So much for a "Sonnet" model -- hopefully it can do Shakespeare at least...
We tested Sonnet 3.5 on our "news story writing" task for DeepNewz. And while not bad, we judged it worse than GPT-4o or Opus 3. It was too verbose. Using it on test examples I found the same thing.
Good model but talks too much. But that's probably ok on other tasks... still expecting it to come in #1 but we'll see.